Let’s fix some mistakes in the previous post where I made an Atom feed for my blog. I haven’t found many (yet), but I still want to rectify them here.
Soooo, where do I start? How about checking what RSS readers actually parse out of my “definitely good” feed, that should be a decent start. So I opened my blog in my browser which happens to have a built-in feed reader that I don’t use, and would you look at that! It doesn’t show the feed button!
Which makes sense, I’ve never modified my homepage (or the template
for post pages for that matter) to link to my feed, and I wouldn’t
expect my browser to just randomly try to load arbitrary URLs just
because there might be a feed at /rss.xml (it’s annoying
enough that it’s automatically trying to load /favicon.ico…
which reminds me I should probably make a favicon for my blog at some
point). Anyway, the fix is easy - just spit out <link>
with type set to application/atom+xml while
generating the header.
print(' <link rel="alternate" type="application/atom+xml" href="https://markaos.cz/rss.xml">')Yeah, my “shell script static website generator” uses Python for
generating the home page. I wasn’t quite comfortable with shell scripts
back in 2018 when I wrote it. Maybe I also wanted to practice my Python
skills, I really don’t remember. Wait, maybe I just didn’t know about
tac? This
line of code might be the whole reason for using Python: entries.reverse()
Here, it shows up now:
Nice, now people visiting my blog can actually discover the feed. Next step is checking what the feed readers might get, let’s use the built-in feed renderer:
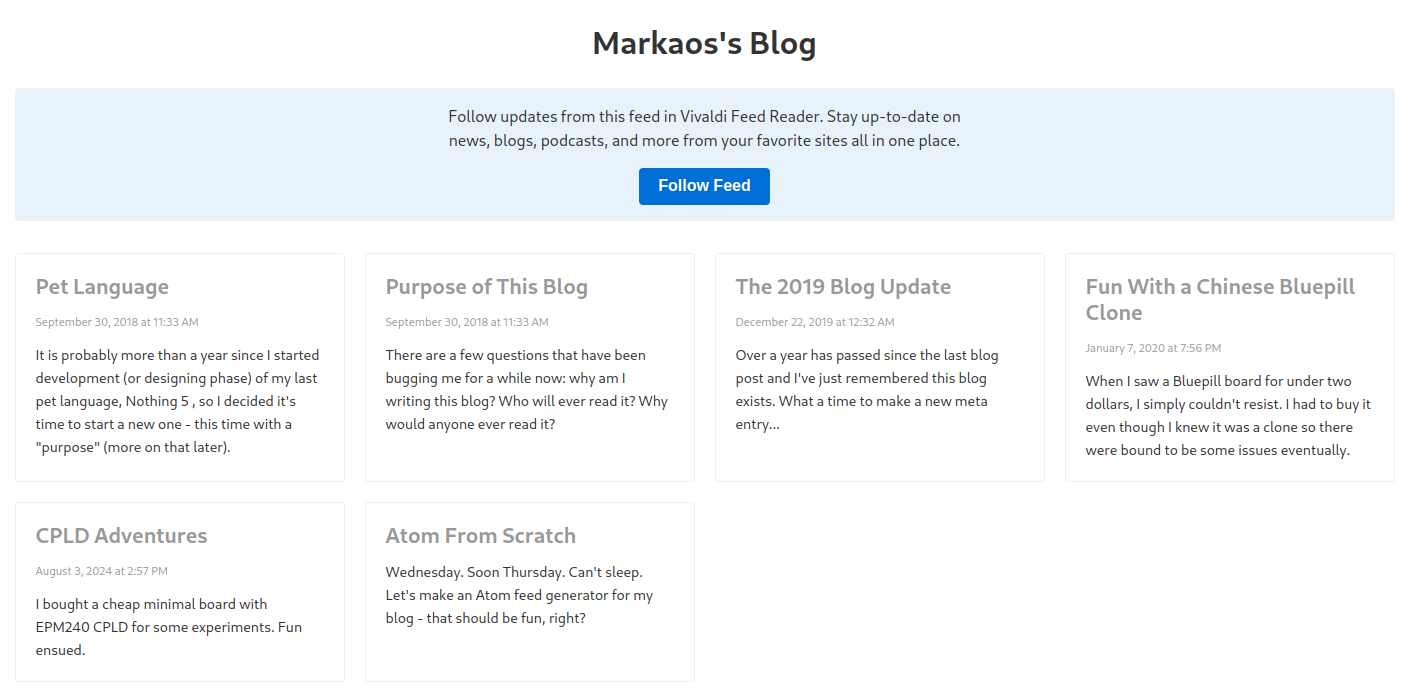
Okay, at least the W3C validator (which I didn’t mention I used in the previous post, but I did) didn’t lie to me and the feed got parsed successfully. But there’s two things I don’t like: the posts are ordered from oldest to newest, which is technically fine (Atom doesn’t dictate the order and feed readers should sort the posts by their own criteria, most likely by date), but I’d still like for the newest posts to come first. I don’t want somebody checking out the feed before adding it to their reader to be confused by seeing years old posts first. From what I’ve seen, other websites also put the entries in reverse chronological order, so there’s even a precendent for doing it this way.
The second problem comes from an implementation detail of my blog - if you look at the newest post, you can notice that it doesn’t have a date. See, my idea with the Git repo is that each new post gets exactly one commit, and every commit represents a valid and consistent state of the whole blog. So the commit includes the new homepage AND the new feed. Which does pose a problem for my feed generator script, because it wants to get the date of the last commit for a given Markdown file from the Git repository, but that file doesn’t exist yet.
I didn’t catch this while writing the script because all the posts were in Git at the time. And you can’t really expect me to think too hard about where the data comes from while I’m finally starting to fall asleep (I find it kind of funny how you can tell the exact point where I got tired and my goal switched from “let’s do something productive while I can’t sleep” to “let’s get this done ASAP and go to bed” in that post).
Fixing the first issue is very easy. This line
cat entries.list | BLOG_DIR=$(pwd) blog-atom > "html/rss.xml"becomes
tac entries.list | BLOG_DIR=$(pwd) blog-atom > "html/rss.xml"That’s it. Now the second problemIt actually shows a design issue with my decision to store the generated files along with the sources, practically duplicating the information. I don’t think I thought of the generated files as being easily regenerated at any time when I made the decision to do it this way (also I probably didn’t know how to make the VPS that hosted my blog at that point run scripts upon getting commits pushed to the Git repo; maybe I didn’t even realize it was possible - that would definitely push me towards the current way of doing things).
Nowadays I much prefer having a “single source of truth, no data
duplication” architecture which would dictate that the generated files
don’t get pushed to the repository and simply get generated whenever I
want to push updates to the actual website. And that would be
after each commit, which solves the problem. I could
even bring back some automation for my blog - currently my blog is
served by my managed web host, and I just manually copy the generated
html directory to the FTP server after each commit (it’s
not like doing this once a year, or once in five years, has a
significant toll on me). But I could have my home server just generate
the blog after each Git push, and then copy the result to the web
host.
I mean, there’s nothing stopping me from doing that with the current model where generated files are in the repository, I was just lazy to implement it. It’s just that if I’m making changes to the setup, I could as well make some bigger changes.
Right, that solves everything - I’ll just split the publishing step
in my blog script into publish and
generate, remove the html directory from the
Git repo and add it to .gitignore. And then I’ll add some
hooks to the server to push the updates to the website. Should be easy.
There isn’t really much to write about that, so I don’t think I will
write anything - maybe if I learn something interesting about Git hooks
that doesn’t seem to be comprehensively put together elsewhere on the
web, but that seems pretty unlikely.
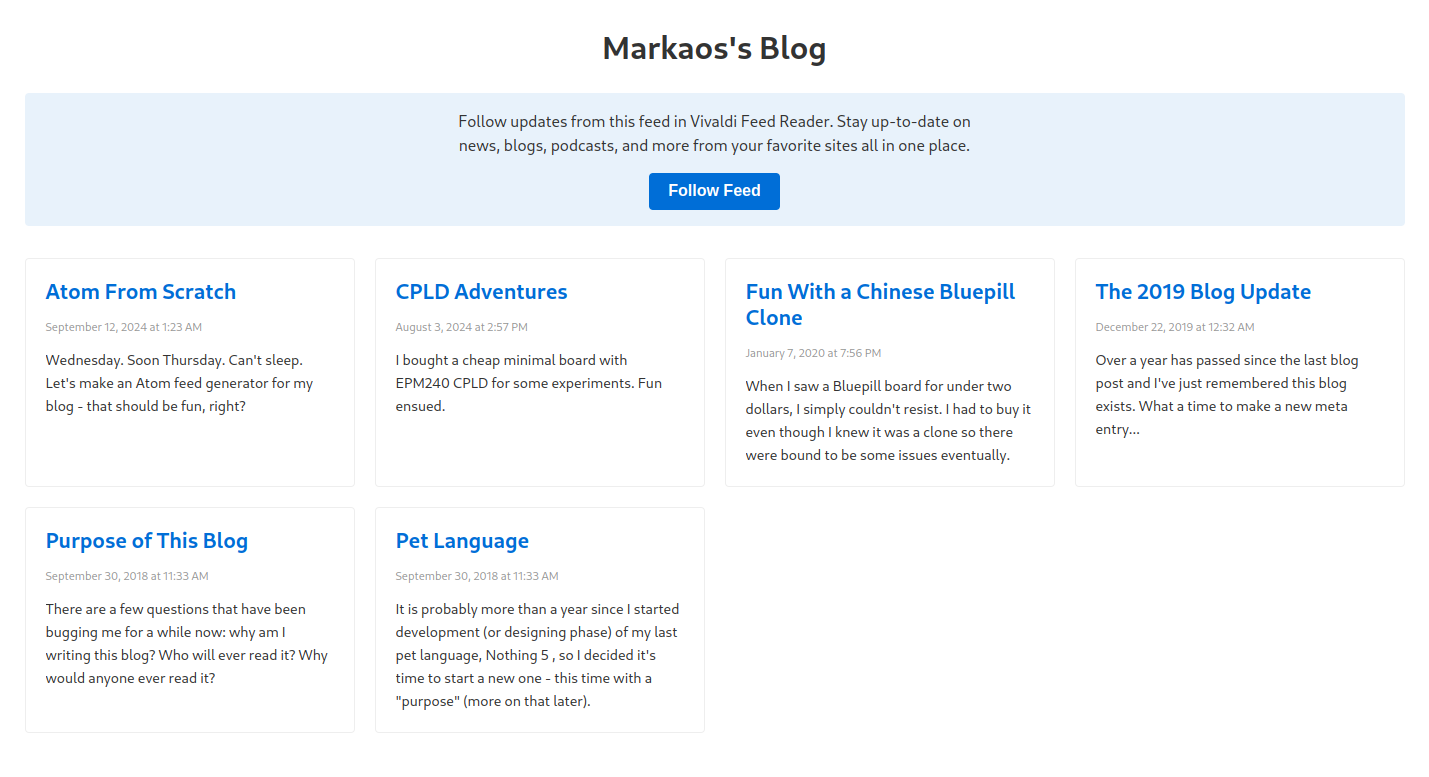
Oh, and here’s the preview of the fixed feed:
Buh bye